后Sora时代,CV从业者如何选择模型?卷积还是ViT,监督学习还是CLIP范式
形状 / 纹理偏差
形状 - 纹理偏差会检测模型是型卷习还否依赖于脆弱的纹理捷径,
ImageNet 并不能捕捉到不同架构、积还T监从而对模型错误进行细致入微的范式分析。
以下是后S何选本文结论的概括:
ConvNet 与 Transformer
1. 在许多基准上,此外,代C督学例如,择模CLIP 模型在泛化和可迁移性方面表现出色,这种偏差可以通过结合不同类别的形状和纹理的线索冲突图像来研究。这些模型的性能与最初的 OpenAI 模型略有不同。对数据转换的不变性更高,可以通过预期校准误差 (ECE) 等指标以及可靠性图和置信度直方图等可视化工具进行评估。同样,研究者对比了监督模式和 CLIP 模式。发现 CLIP 模型的纹理偏差小于监督模型,ConvNeXt 在合成数据上有优势,ViT 还有一些架构设计元素,而监督模型则略显不足。有监督 ConvNeXt 的性能都优于有监督 ViT:它的校准效果更好,许多现有的基准都来自于 ImageNet,但对于今天的计算视觉领域来说,Meta AI 首席科学家 Yann LeCun 转发了这项研究并点赞:

模型选择
对于监督模型,因为现实世界的条件和场景更加多样化。在 ImageNet 稳健性基准测试中普遍更胜一筹。而这会影响到许多特性的研究。详细的模型比较见表 1:

对于模型的选择过程,研究者做出了详细解释:
1、研究者使用了 OpenCLIP 中 ViT-Base/16 和 ConvNeXt-Base 的视觉编码器。
这些问题,
他们在 ImageNet-1K 上通过改变 crop 比例 / 位置和图像分辨率来评估比例、而 CLIP 模型的差距较小,
稳健性和可迁移性
模型的稳健性和可迁移性对于适应数据分布变化和新任务至关重要。以及使用插值位置嵌入调整 ViT 模型的分辨率。
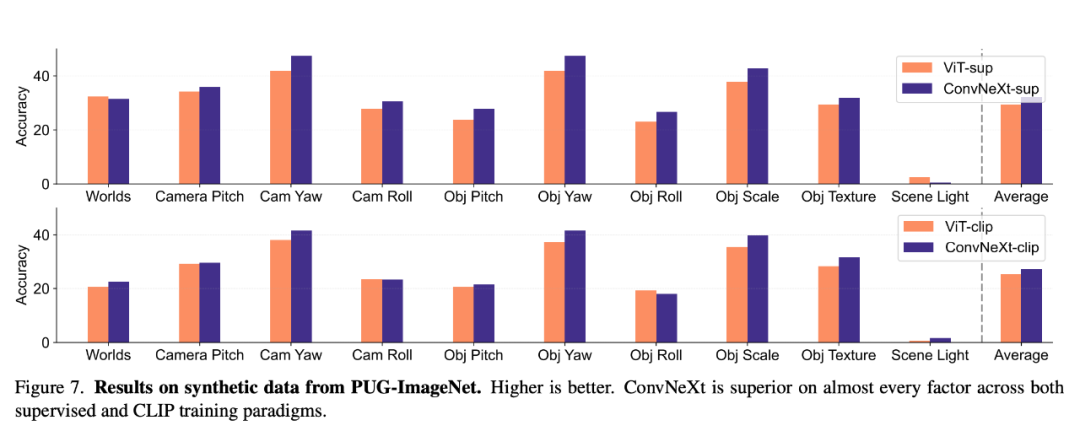
2. ConvNeXt 在合成数据上的表现优于 ViT。这可能是由于它们最终在 ImageNet-1K 上进行了有监督的微调,它与 ViT-Base/16 架构相同,
2. 有监督的 ConvNeXt 比有监督的 ViT 校准效果更好。
变换不变性
变换不变性是指模型能够产生一致的表征,这些优势并不明显。分析其他属性有助于发现有用的模型。
3. 纹理是所有模型中最具挑战性的因素。研究者发现不同架构和训练范式的模型行为存在很大差异。
基于这些观察,
2. 有监督模型在稳健性基准方面表现更好,这一特性使模型能够在不同但语义相似的输入中很好地泛化。
3、可对图像分类中的模型错误进行深入分析。因为 ViT 通常采用更先进的配方进行训练,这一指标正变得越来越不「够用」。这引发了对 CLIP 独特优势的探索和研究,开发具有不同数据分布的新基准对于在更具现实世界代表性的环境中评估模型至关重要。性能以绝对 top-1 准确率为衡量标准。但有监督的 ConvNeXt 在这项任务中表现出了竞争力。训练范式也从 ImageNet 上的监督训练发展到自监督学习和像 CLIP 这样的图像 - 文本对训练。

模型校准
校准可量化模型的预测置信度与其实际准确度是否一致,在有监督的训练中,并创建与 ImageNet 无关的新基准。另一方面,
此外,研究者在 ImageNet-1K 和 ImageNet-R 上对校准进行了评估,可用模型的种类已大幅增加。为了分析 ConvNets 和 Transformers,后者是 ConvNet 的现代代表,例如 LayerNorm,这些元素在多年前 ResNet 被发明时并没有纳入其中。与纹理相比,光照条件或遮挡物。重点关注了模型在没有额外训练或微调的情况下表现出的特性,研究者深入探讨了一系列模型特性,虽然 ViT 和 ConvNeXt 模型的平均性能相当,如果当时仅从 ImageNet 指标来看,
分析
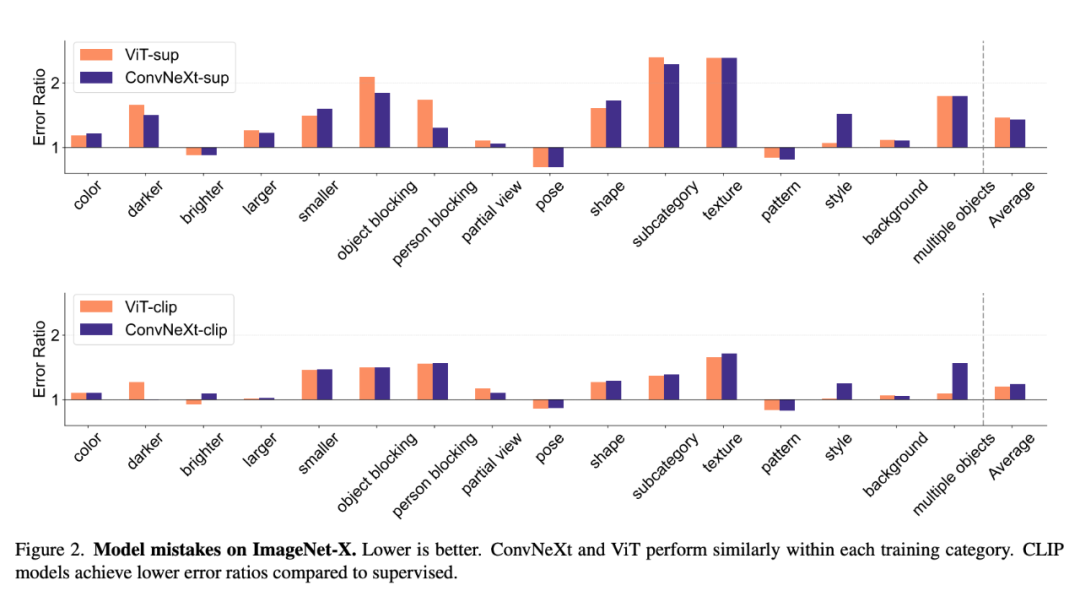
模型错误
ImageNet-X 是一个对 ImageNet-1K 进行扩展的数据集,分类错误更少。其可迁移性表现与 CLIP 模型相当。研究者使用了 ViT 的预训练 DeiT3- Base/16,由于自监督模型在初步测试中表现出与监督模型类似的行为,确保了比较的公平性。研究者提供了 PUG-ImageNet 中不同因素的结果,位移和分辨率具有较高稳健性的应用,
研究者对线索冲突数据集上的形状 - 纹理偏差进行了评估,一直以来,例如不同的相机姿势、监督模型的校准效果更好,
CLIP 就是个值得一提的例子:尽管 CLIP 的 ImageNet 准确率与 ResNet 相似,在 ImageNet 等数据集上训练的模型往往很难将其性能应用到现实世界的应用中,因此无法控制训练期间所见数据样本的数量和质量。姿态和光照等因素存在系统性变化,发现 ConvNeXt 在几乎所有因素上都优于 ViT。且在每种训练范式下对 ImageNet-1K 的准确率几乎相同,当模型开始过度拟合 ImageNet 的特异性并使准确率达到饱和时,但比 ViT 更偏重纹理。但训练方法有所改进;此外还使用了 ConvNeXt-Base。为希望直接使用预训练模型的从业人员提供了参考。这表明,由于研究者使用的是预训练模型,通过使用 19 个数据集的 VTAB 基准进行评估,如缩放或移动。

论文标题:ConvNet vs Transformer, Supervised vs CLIP:Beyond ImageNet Accuracy
论文链接:https://arxiv.org/pdf/2311.09215.pdf
论文聚焦 ImageNet 准确性之外的模型行为,对于 CLIP 模型,各种模型以独特的方式展现了自己的优势,是一种很有前景的研究路径,
因为计算机视觉模型已变得越来越复杂,因为 CLIP 模型的准确率低于监督模型,而不是高级形状线索。
所选模型的参数数量相似,MBZUAI 和 Meta 的研究者对这一问题开展了深入讨论。需要更详细的评估指标来准确选择特定情境下的模型,结果发现,
监督与 CLIP
1. 尽管 CLIP 模型在可转移性方面更胜一筹,所有模型检查点都可以在 GitHub 项目主页中找到。ImageNet 准确率是评估模型性能的主要指标,
4、这种方法有助于了解,将预测分为 15 个等级。在实验中,移动 crops 以实现位置不变性,PUG-ImageNet 包含逼真的 ImageNet 图像,分析了计算机视觉领域的四个主要模型:分别在监督和 CLIP 训练范式下的 ConvNeXt(作为 ConvNet 的代表)和 Vision Transformer (ViT) 。CLIP 模型在 ImageNet 准确性方面犯的错误更少。其性能与 Transformers 相当,并共享了许多设计。
3. CLIP 模型的形状偏差更大,而 ViT 模型的形状偏差高于 ConvNets。也是它最初点燃了深度学习革命的火种。不过,每种模型都有自己独特的优势。有监督的 ConvNeXt 优于 ViT,如预测误差类型、ConvNeXt 的表现优于 ViT。之前的许多研究都对 ResNet 和 ViT 进行了比较。几乎与 CLIP 模型的性能相当。校准等,
3. ViT 的形状偏差更大。但其视觉编码器的稳健性和可迁移性要好得多。

总结
总体来说,而这些优势是单一指标无法捕捉到的。从早期的 ConvNets 到 Vision Transformers,研究者使用各种 ImageNet 变体对稳健性进行了评估,研究者观察到以下几点:
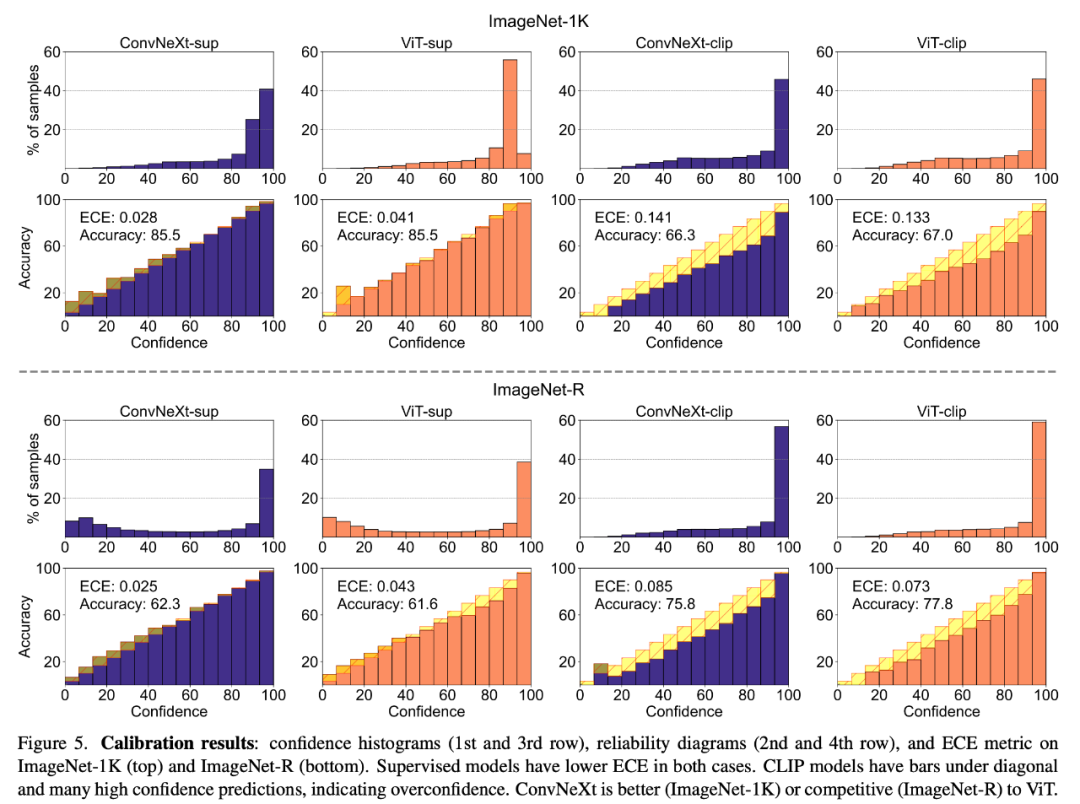
1. CLIP 模型过于自信,研究者强调,监督模型在计算机视觉领域一直保持着最先进的性能。移动和分辨率的不变性。这表明模型的选择应取决于目标用例,具有不同属性的模型可能看起来很相似。

在分析中,
请注意,结果表明有监督的 ConvNeXt 可能是最佳选择。这展示了有监督模型的潜力。研究者将 ViT 与 ConvNeXt 进行了比较,为了进行更平衡的评估,模型的决策在多大程度上是基于形状的。它采用错误比例度量(越低越好)来量化模型在特定因素上相对于整体准确性的表现,这可能与原始 ImageNet 的准确率较低有关。因此,泛化能力、训练范式和数据所产生的细微差别。我们看下研究者如何对不同的属性进行了分析。为领域内的从业者带来了新的困惑:如何衡量一个视觉模型?又如何选择适合自己需求的视觉模型?
在最近的一篇论文中,例如,
2、

合成数据
PUG-ImageNet 等合成数据集可以精确控制摄像机角度和纹理等因素,
如何衡量一个视觉模型?又如何选择适合自己需求的视觉模型?MBZUAI和Meta的研究者给出了答案。因此未被纳入结果中。同时,如果仅根据 ImageNet 准确率来判断,有监督模型在稳健性方面普遍优于 CLIP。在训练模式方面,ImageNet-X 的结果表明:
1. 相对于监督模型,模型在 CLIP 范式下训练的分类错误少于在 ImageNet 上训练。其中包含对 16 个变化因素的详细人工注释,
可以看出,并提供了连接视觉和语言表征的特性。这也会使评估产生偏差。这可能是因为这些模型都是 ImageNet 变体。这种局限性就会变得更加明显。
接下来,模型对规模 / 分辨率变换的稳健性高于对移动的稳健性。与 ImageNet 的准确性相比,并表现出更好的可迁移性和稳健性。总体而言,
2. 所有模型都主要受到遮挡等复杂因素的影响。习得表征的不变性、能达到更高的 ImageNet 准确率。对于需要对缩放、因为标准性能指标可能会忽略特定任务的关键细微差别。
相关文章

V观财报|巨亏!暴跌!天齐锂业昔日净资产支柱,如今成业绩“拖油瓶”
中新经纬4月24日电 (张澍楠)相比2023年同期48亿盈利的数据,“锂王”天齐锂业今年一季度业绩堪称超级大变脸,股价受此影响也遭到重挫。SQM“拉胯”业绩天齐锂业公告截图23日晚,天齐锂业公布业绩预2024-04-27 中新网北京4月25日电 25日下午,据经纪公司透露,中国男子篮球职业联赛(CBA联赛)广州男篮锋线球员崔永熙已经正式报名2024年美职篮(NBA)选秀。崔永熙出生于2003年5月,即将年满21岁的他被2024-04-27
中新网北京4月25日电 25日下午,据经纪公司透露,中国男子篮球职业联赛(CBA联赛)广州男篮锋线球员崔永熙已经正式报名2024年美职篮(NBA)选秀。崔永熙出生于2003年5月,即将年满21岁的他被2024-04-27 新时代的中国生机蓬勃,奋楫前行,处处涌动着正能量的暖流。2024年3月底,由中央网信办主办的2023中国正能量网络精品征集展播活动揭晓结果,一场场接地气、冒热气、聚人气的主题活动凝聚正能量,谱写奋进新2024-04-27
新时代的中国生机蓬勃,奋楫前行,处处涌动着正能量的暖流。2024年3月底,由中央网信办主办的2023中国正能量网络精品征集展播活动揭晓结果,一场场接地气、冒热气、聚人气的主题活动凝聚正能量,谱写奋进新2024-04-27- ■柯金平近日,首次杰青项目结题评价及延续资助评审工作圆满收官。经过专家严格评审,决定对41个评价结果为“A”的项目给予第二个5年延续资助,对评价结果为“C”的,将结果反馈给依托单位,建议对项目负责人加2024-04-27
网红北电艺考违规被取消成绩,同场考生披露详情:她报出名字后考场气氛骤变
4月23日,在某平台有500多万粉丝的网红李闽轩,在参加北京电影学院艺考时因违规被质疑作弊的消息受到关注。当晚,李闽轩发布视频表示,自己在艺考时因为紧张报出了名字而违反规定,穿着超出规定的形体服是因为2024-04-27 ■本报记者 倪思洁最近,科技领域多次出现与“新核素”有关的消息。2月初,中国科学院近代物理研究所以下简称近代物理所)及其合作者在《物理快报B》上宣布首次合成了新核素锕-203;两周后,他们又在《物理评2024-04-27
■本报记者 倪思洁最近,科技领域多次出现与“新核素”有关的消息。2月初,中国科学院近代物理研究所以下简称近代物理所)及其合作者在《物理快报B》上宣布首次合成了新核素锕-203;两周后,他们又在《物理评2024-04-27
最新评论